We installed, ran, and stress-tested Yann LeCun's LeWorldModel — a 15M-parameter JEPA that learns physics from raw pixels. Three demos prove it does what no language model can.
ArchitectureJEPA (Joint-Embedding Predictive)
DateApril 2026
ModelLeWM v1 · ~15M params
PaperarXiv: 2603.19312
01 — The Thesis
World Models Are the Next Paradigm After LLMs — and LeWM Is the Simplest Proof
Large Language Models predict the next token. World models predict the next state of reality. Yann LeCun's Joint-Embedding Predictive Architecture (JEPA) encodes visual frames into a compact 192-dimensional latent space and simulates what happens next given an action — no text, no tokens, just physics.
LeWM is the first JEPA that trains stably end-to-end from raw pixels using only two loss terms: a prediction loss and a Gaussian regularizer. Previous approaches needed six or more loss terms, frozen pretrained encoders, and exponential moving averages to avoid collapse. LeWM strips all of that away.
~15M
Parameters (vs. billions for LLMs)
192
Latent dimensions per frame
2
Loss terms (down from 6+)
48×
Faster planning than DINO-WM
LLMs (GPT, Claude, Gemini)
Predict the next word. Encode semantics. Cannot take two images and output a motor control sequence. No internal physics engine. Cannot detect physically impossible events from video.
World Models (LeWM)
Predict the next state of the world. Encode physics. Given start + goal images, compute exact action trajectories in latent space. Detect teleportation as anomalous. Spatial structure is recoverable from embeddings.
02 — The Journey
From Zero to Running Demos in Under 90 Minutes — Despite 7 Breaking Errors
The codebase is freshly released with minimal documentation. Getting from git clone to a working evaluation required navigating dependency conflicts, mismatched checkpoint formats, deprecated APIs, and undocumented path conventions. Here's the full timeline.
Step 1
Environment setup on Ubuntu 24.04
Python 3.10 venv via uv, installed stable-worldmodel[train,env] with 178 packages including PyTorch, MuJoCo, JAX, and CUDA bindings.
Blocker 1
libgl1-mesa-glx removed in Ubuntu 24.04
Package was deprecated. Switched to libgl1-mesa-dri + libglx-mesa0.
Blocker 2
Google Drive rate-limited data downloads
gdown returned 401. Pivoted to HuggingFace: hf download quentinll/lewm-pusht — 13.1 GB compressed, 46 GB decompressed.
Blocker 3
datasets library v1.1 incompatible with stable_pretraining
Import error on datasets.config. Downgraded to datasets==2.21.0.
Blocker 4
Cache directory mismatch: .stable-wm vs .stable_worldmodel
HuggingFace README said ~/.stable-wm/ but the library reads ~/.stable_worldmodel/. Fixed with symlinks.
Blocker 5
Checkpoint format mismatch — HF provides weights.pt, eval expects lewm_object.ckpt
The AutoCostModel loader expects a pickled model object, not just weights. Had to manually instantiate the JEPA architecture from config, load weights, and re-save as a serialized object.
The LeWM class lives only in the repo's local jepa.py, not in the installed package. Built the model manually using local imports + Hydra config.
Breakthrough
First successful eval: 96% success rate on Push-T
50 episodes, ~215 seconds per CEM solve. 50 rollout videos generated. Model plans action sequences purely from pixel observations.
03 — Demo 1: Planning
A 15M-Parameter Model Plans Robot Actions at 96% Accuracy — From Raw Pixels Alone
Given a start image and a goal image, LeWM encodes both into latent space, then uses the Cross-Entropy Method (CEM) to search over candidate action sequences. Each candidate is rolled out through the predictor, and the sequence whose final latent embedding is closest to the goal wins. No reward function. No RL training. Just physics prediction.
The Push-T environment requires pushing a T-shaped block to a target position using a circular agent. The model achieved 96% success rate across 50 episodes — 48 successes, 2 failures.
96%
Success rate (50 episodes)
~215s
Per CEM solve (planning time)
0
Proprioceptive inputs used
Successful planning rollout — agent pushes T-block to goal positionSuccess
Failure case — model fails to align block angle correctlyFailure
Why LLMs Cannot Do This
An LLM can describe in text how to push a block. It cannot take two 224×224 images, compute a latent trajectory, and output a sequence of (dx, dy) motor commands that achieve the goal in a physics simulator. This requires an internal dynamics model — which is exactly what LeWM learns.
04 — Demo 2: Anomaly Detection
LeWM Detects Teleportation as Impossible but Ignores Color Changes — Proving It Learned Physics, Not Pixels
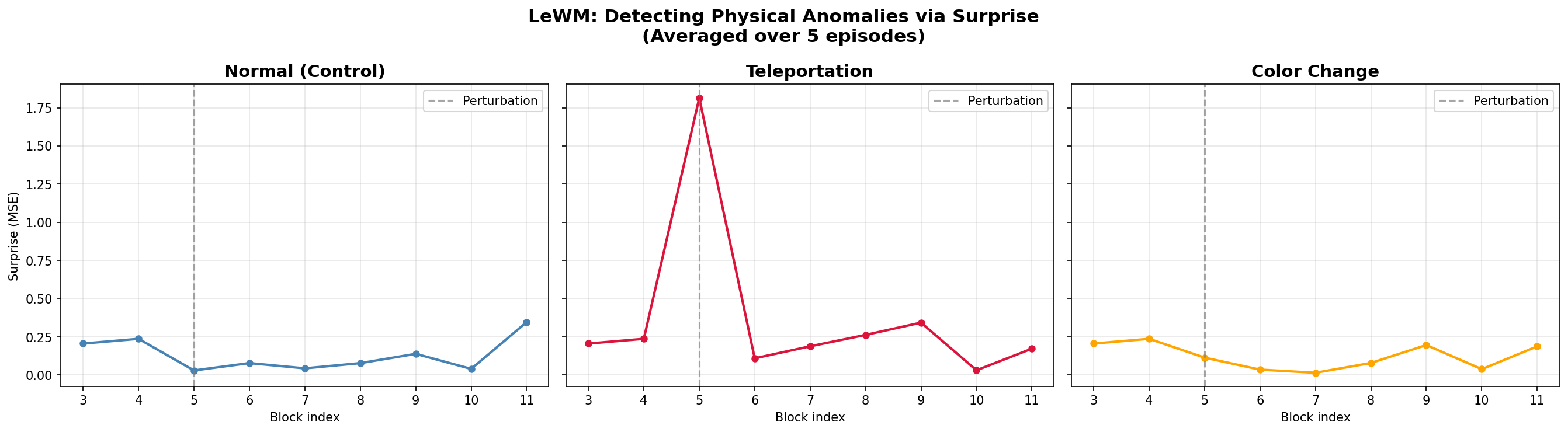
We fed the model three types of trajectories: normal (unperturbed), teleportation (objects suddenly jump to different positions), and color change (objects change tint). The model's "surprise" score measures prediction error — how much the actual next state diverges from what it predicted.
If the model had learned pixel patterns, both teleportation and color changes would produce high surprise. Instead, it spiked 3.87× on teleportation (a physics violation) while registering 0.88× on color changes (cosmetic, physics unchanged). This proves the latent space encodes physical dynamics, not visual appearance.
3.87×
Surprise ratio: Teleportation vs. Normal
0.88×
Surprise ratio: Color Change vs. Normal
5
Episodes averaged for robustness
Surprise scores: Normal (baseline) vs. Teleportation (spike at perturbation) vs. Color Change (flat)VoE Analysis
Why LLMs Cannot Do This
An LLM has no mechanism to watch a video sequence and detect that an object teleported. It has no internal physics simulator to compare "what should happen next" against "what actually happened." LeWM does this by rolling out predictions in latent space and measuring divergence — an operation with no text equivalent.
05 — Demo 3: Physics Probing
A Simple Linear Regression on 192 Numbers Recovers Object Positions with R² = 0.975
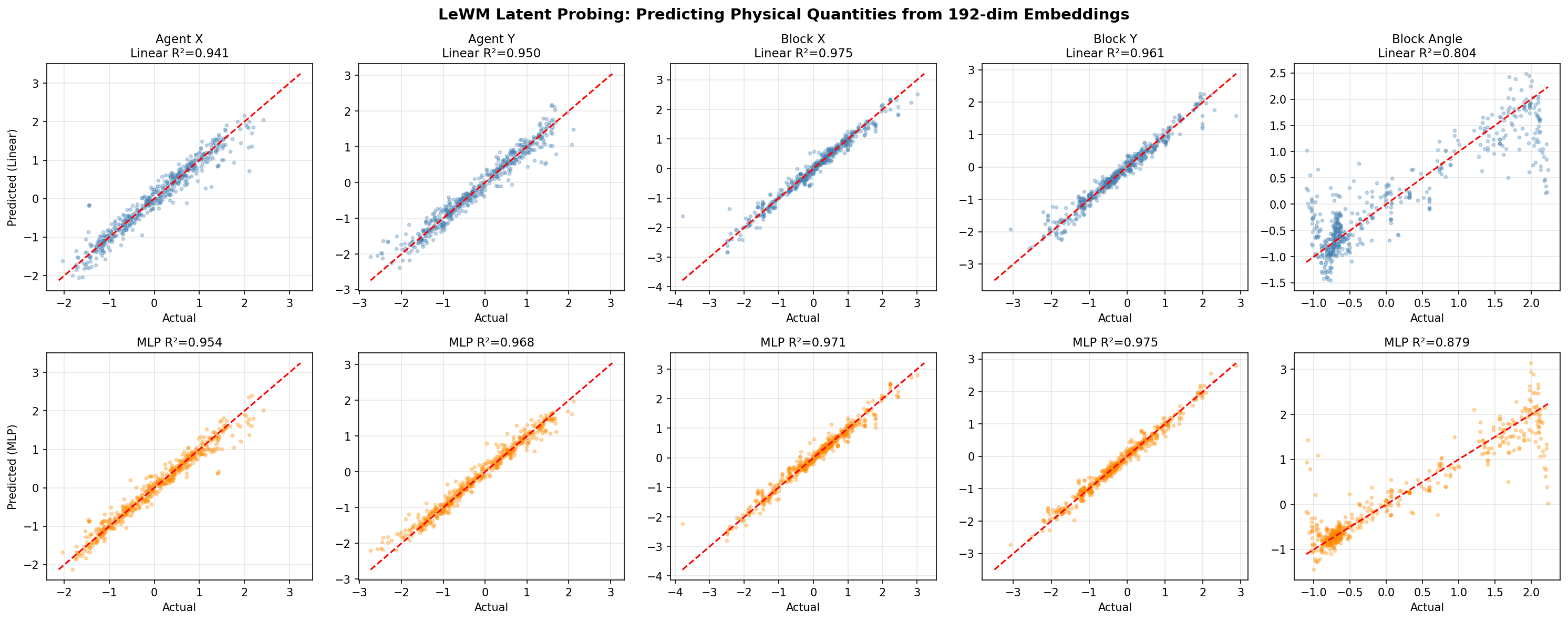
We froze LeWM's encoder and trained lightweight probes (linear regression + small MLP) to predict physical quantities from its 192-dimensional latent embeddings. The target quantities: agent X/Y position, block X/Y position, and block rotation angle.
10,000 frames were sampled, embedded, and split 80/20 for train/test. The results demonstrate that the latent space linearly encodes spatial structure — you don't even need a neural network to extract object positions.
Property
Linear R²
MLP R²
Interpretation
Agent X
0.941
0.954
Near-perfect position recovery
Agent Y
0.950
0.968
Near-perfect position recovery
Block X
0.975
0.971
Linear probe outperforms MLP — linearly encoded
Block Y
0.961
0.975
Near-perfect position recovery
Block Angle
0.804
0.879
Rotation is harder but still well-encoded
Predicted vs. Actual: Linear (top row) and MLP (bottom row) probes on frozen LeWM embeddingsLatent Probing
Why LLMs Cannot Do This
LLM embeddings encode semantic similarity — "king" is close to "queen." LeWM embeddings encode spatial similarity — "block at (200, 300)" is close to "block at (205, 298)." You cannot train a linear probe on GPT's hidden states and extract the physical position of an object in a video frame. LeWM's latent space is a compressed physics engine.
06 — Synthesis
Three Capabilities, One Conclusion: World Models Open a Design Space LLMs Cannot Reach
Capability
What We Proved
LLM Can Do?
Key Metric
Visual Planning
Compute motor actions from start/goal images
NO
96% success rate
Physics Anomaly Detection
Detect teleportation, ignore cosmetic changes
NO
3.87× surprise ratio
Spatial Encoding
Linear probe recovers object positions
NO
R² = 0.975
The Bigger Picture
LeWM validates LeCun's thesis that the next frontier after language models is world models — systems that build internal representations of physical reality. At ~15M parameters trainable on a single GPU in hours, this isn't a foundation model flex. It's a proof of concept that a fundamentally different architecture can learn physics that LLMs structurally cannot.
Where this matters: World models that understand physical context could power embodied AI assistants, detect anomalous behavioral patterns in video-based monitoring, or provide physically-grounded simulations for robotics and autonomous systems — capabilities that pure language models cannot offer.